

Co-Founder Innovation Geeks
Understanding YOLO Algorithm: Revolutionizing Object Detection in Machine Learning
In the realm of machine learning, object detection has always posed a significant challenge. The ability to not only identify objects within an image but also accurately locate them is a fundamental task with a multitude of real-world applications. Enter YOLO (You Only Look Once), an innovative object detection algorithm that has taken the field by storm. In this blog, we'll delve into the workings of YOLO and explore how it sets itself apart from other object detection algorithms.
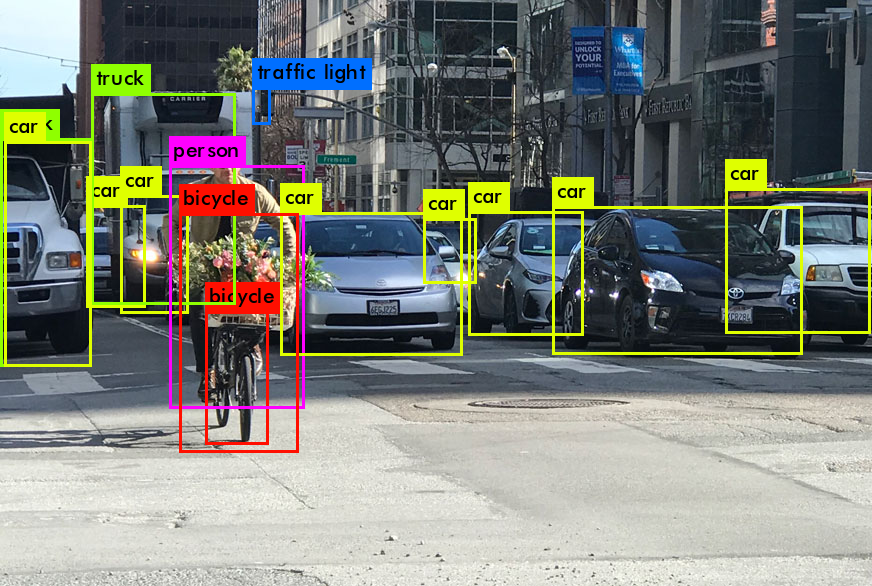
What is YOLO Algorithm?
YOLO, short for "You Only Look Once," is a deep learning-based algorithm that has dramatically transformed the landscape of object detection. Unlike traditional methods that involve multiple stages like region proposal and classification, YOLO adopts a different approach. It treats object detection as a regression problem and operates on the entire image in a single pass.
How YOLO Works: The Inner Mechanisms
The core principle behind YOLO's functioning is simplicity and efficiency. It divides the input image into a grid and predicts bounding boxes, class probabilities, and objectness scores for each grid cell. Here's a step-by-step breakdown of how YOLO works:
- Grid Division:The input image is divided into a grid, with each grid cell responsible for predicting objects that fall within it.
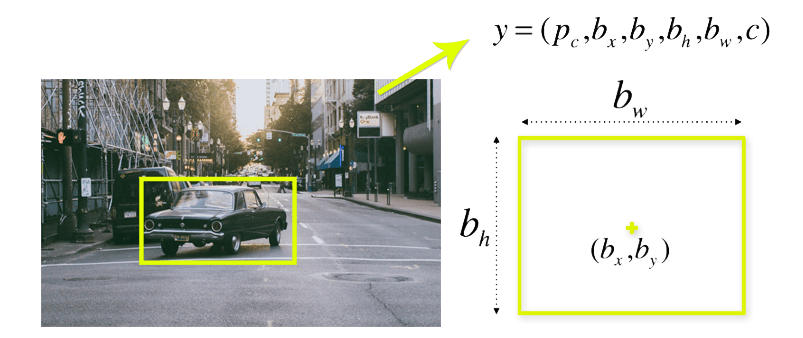
- Bounding Box Prediction: For each grid cell, YOLO predicts one or more bounding boxes, each represented by its coordinates (x, y) of the center, width, height, and the confidence score. The confidence score reflects the model's confidence in the presence of an object within the box.
- Class Prediction: YOLO also predicts the probabilities of various classes for each bounding box. This means that each grid cell not only predicts the objects but also their respective classes.
- Objectness Score: In addition to the confidence score, YOLO calculates an objectness score that estimates how likely it is that the bounding box contains an object.
- Non-Maximum Suppression:After predictions are made, YOLO employs non-maximum suppression to eliminate duplicate detections and retain the most accurate one. This step helps in avoiding multiple redundant bounding boxes around the same object.

Evolution of YOLO: Different Versions
The YOLO (You Only Look Once) algorithm has seen several iterations, each building upon the strengths of the previous versions. These advancements have enabled YOLO to find its way into a wide range of real-time applications. Let's explore the different versions of YOLO and its practical applications.
- YOLOv1 (You Only Look Once v1):
The original YOLOv1 introduced the concept of a single-pass object detection algorithm that revolutionized the field. Although it laid the foundation for subsequent versions, it had limitations in detecting small objects and precise localization due to the fixed grid structure. - YOLOv2 (YOLO9000 or YOLOv2):
YOLOv2 addressed the shortcomings of its predecessor by introducing various improvements, such as multi-scale training, anchor boxes for better bounding box predictions, and finer-grained predictions through feature extraction at multiple scales. This version also combined YOLO with a classifier to predict object classes, resulting in higher accuracy. - YOLOv3:
YOLOv3 further refined the algorithm's accuracy and detection capabilities. It incorporated a feature pyramid network (FPN) to handle objects of different sizes more effectively. Additionally, YOLOv3 introduced three different sizes of detection grids, enabling the detection of objects at varying scales. This version achieved impressive results on both accuracy and speed fronts. - YOLOv4:
YOLOv4 took a significant leap forward in terms of performance and capabilities. It integrated several advanced techniques such as CSPDarknet53 as the backbone network, PANet for feature fusion, SAM (Spatial Attention Module) for improved spatial sensitivity, and more. YOLOv4 set new standards in accuracy while still maintaining real-time detection capabilities. - YOLOv5:
YOLOv5 continued the trend of innovation with focus on streamlined architecture and efficiency. It introduced novel concepts like a CSPDarknet53 backbone, PANet-lite for feature aggregation, and advanced data augmentation techniques. YOLOv5 offered competitive accuracy with significantly improved inference speed, making it even more suitable for real-time applications.
Key Advantages of YOLO Algorithm
- Real-time Detection: One of YOLO's biggest strengths is its speed. Since it processes the entire image in one pass, it can achieve real-time object detection, making it suitable for applications like autonomous driving, video surveillance, and robotics.
- Accuracy and Efficiency:YOLO optimizes both accuracy and efficiency. Its single-stage architecture eliminates the need for multiple passes, reducing computation time while still maintaining high accuracy.
- Handling Small Objects:YOLO excels at detecting small objects, which can be challenging for some other algorithms. Its grid-based approach ensures that small objects are not overlooked, improving overall detection performance.
- End-to-end Learning: YOLO's end-to-end learning process allows it to learn directly from raw image data, simplifying the pipeline and potentially improving performance.
In conclusion, YOLO has brought about a paradigm shift in object detection. Its streamlined, single-pass approach, coupled with its balance between accuracy and efficiency, has made it a cornerstone for real-time applications. As technology continues to advance, YOLO's principles are likely to continue shaping the future of object detection and its myriad applications across industries.